SEO Suite Content Suite AI Suite Preise Einloggen
SEO Suite Content Suite AI Suite Preise EinloggenMit uns explodiert
dein organischer Traffic!
dein organischer Traffic!
Unsere Software wurde nur zu einem Zweck entwickelt:
Deine Webseiteninhalte bei Google auf die Top-Position zu bringen.
Nutze diesen Wettbewerbsvorteil und steigere deinen Umsatz!
Deine Webseiteninhalte bei Google auf die Top-Position zu bringen.
Nutze diesen Wettbewerbsvorteil und steigere deinen Umsatz!

ContentSuite, SeoSuite & AiSuite
Unsere drei Produkte für deinen Rankingerfolg
Ob technische Optimierung, Content-Erstellung oder KI-gestützte Analysen – unsere drei Suiten decken alle Bereiche ab, die du für nachhaltige Top-Rankings brauchst.
SEO Suite
Die SEO Suite ist eine Software, die dir hilft, deine Website für Suchmaschinen zu optimieren. Du kannst die SEO Suite verwenden, um deine Website zu analysieren und zu optimieren, um sie für Suchmaschinen wie Google zu verbessern.
Mehr erfahren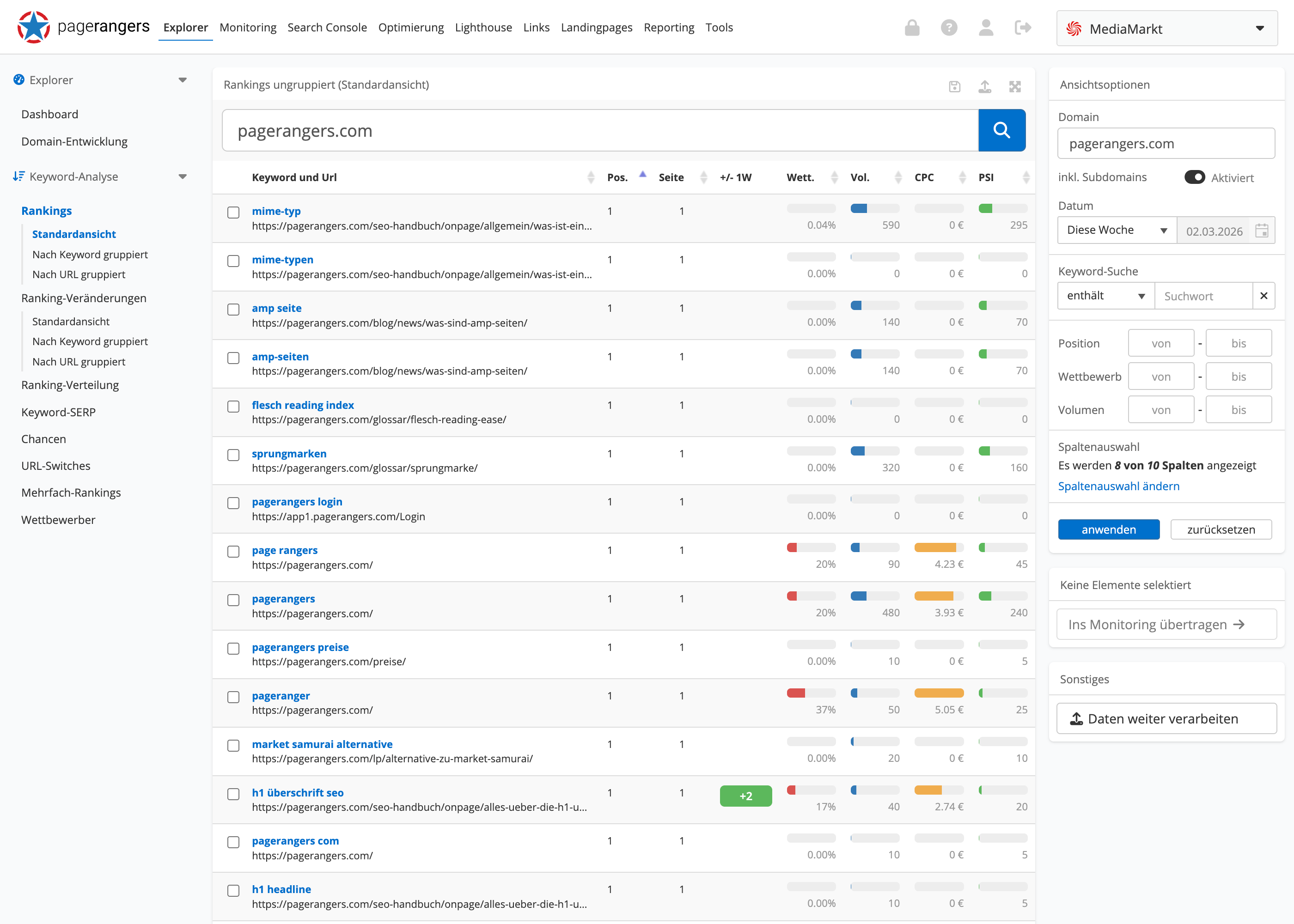
ContentSuite
Das Flaggschiff! Die #1 im Bereich der Content-Optimierung im deutschsprachigen Raum. Die umfangreichste Toolbox um jeden Aspekt abzudecken, der bei der Content-Erstellung von Bedeutung ist.
Mehr erfahren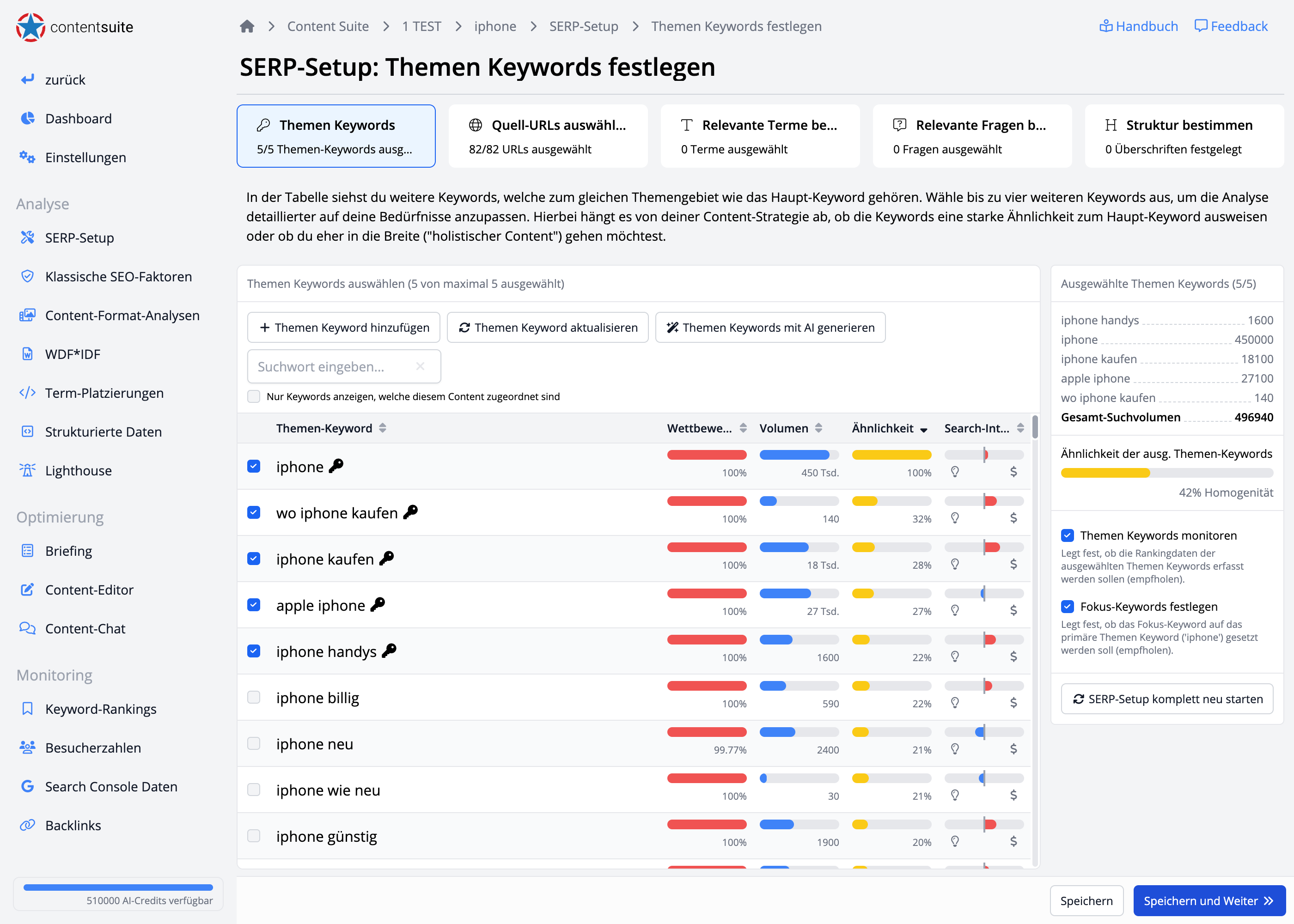
AiSuite
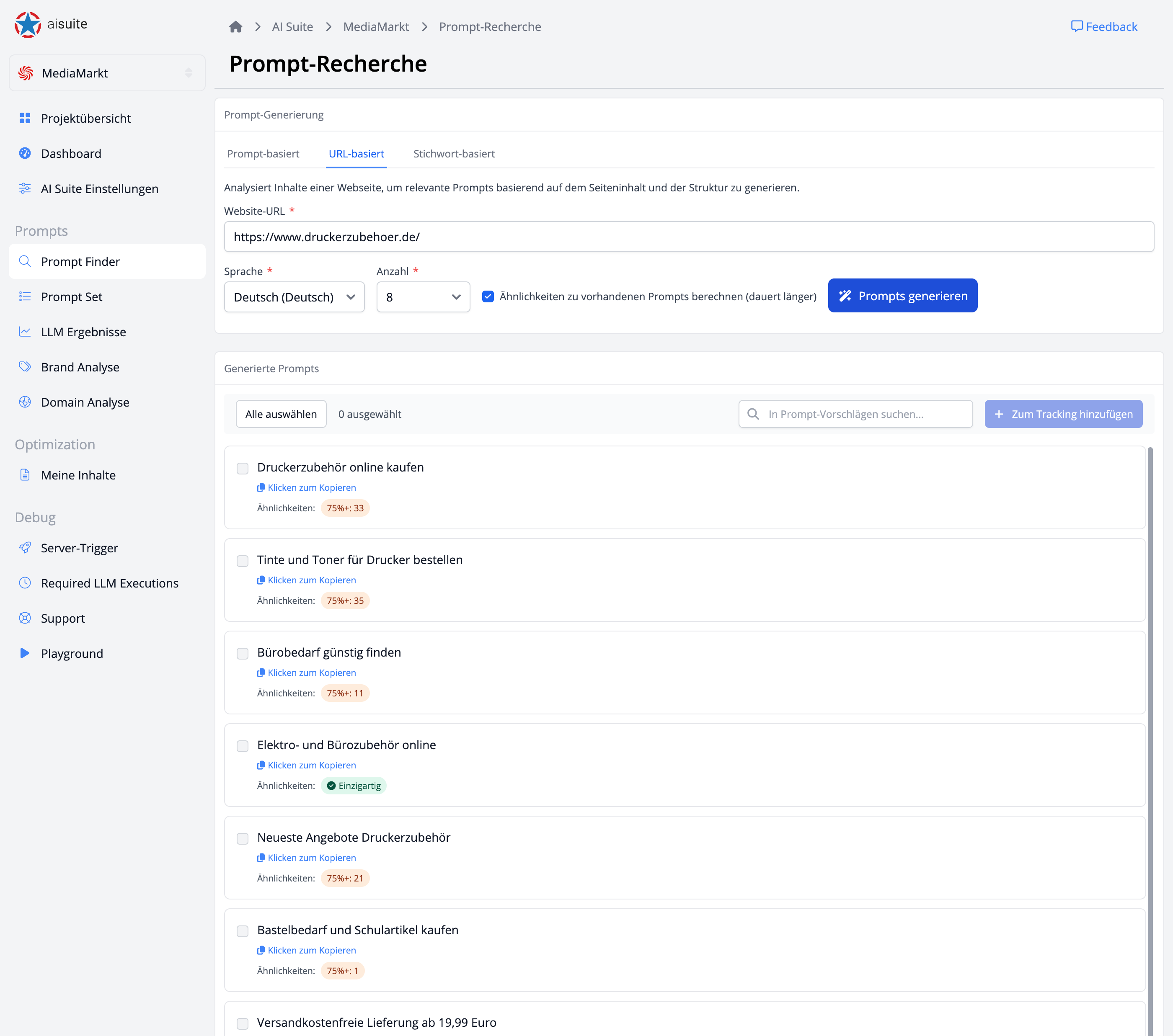
Analysiere die Sichtbarkeit deiner Domain und Marke in KI-Modellen wie ChatGPT, Gemini und Perplexity. Mit dem mehrstufigen Prompt-Finder, Wettbewerbsanalysen und integriertem Text-Editor optimierst du deine Inhalte gezielt für KI-Systeme.
Mehr erfahren